
概述
机器学习理论由紧密联系而又自成体系的三个模块所构成,分别是:模型、学习和推断。其中,模型为具体的问题域提供建模工具;学习是理论核心,为设定学习目标和学习效果提供理论保证;推断关注模型的使用性能和准确性。

本文的目的是对机器学习的总体理论框架做总结,提供原理性地解释。本文不会对具体的模型、算法做讲解(这些内容在相关的教材上都可以找到),只会对各模型、算法间的联系性做说明,以便帮助读者建立一个结构化的知识体系。目标读者需要对机器学习的基本原理、各种模型和算法已经有所了解和掌握。
一
模型=假设=规律
模型的本质
形式上,模型就是一个带有参数的函数表达式,我们希望模型能够反映某种关系或规律。早在机器学习出现之前,人们就已经通过对周围世界的观察,归纳出了很多模型。例如,物理学中的万有引力定律
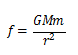
和质能方程式。这些模型非常稳定(至少在我们所在的宇宙是这样子的)、适用性很强。然而,还有许许多多的规律( 一般都局限在各个具体的研究领域),虽然适用性小一些,但却实实在在的影响了我们的生活,值得我们去发掘。发现这些规律的过程依赖于我们的观察。随着传感器技术的发展,人为的观察过程逐渐被机器所取代,观测的结果以电子化数据的方式被存储下来。基于统计学和计算机科学,人们希望从这些数据中发现某些统计规律,并将发现的规律应用于生产实践。由此,便产生了机器学习这一学科。
回到刚才说的模型,一个看起来显而易见但却是本质性的问题是:为什么需要模型?如果我们能够收集到包含足够信息的数据,是否可以直接发现规律,而跳过建模的过程呢?毕竟,机器学习领域已经提出了很多“model-free”的思路。
答案是:不能。
要理解这个问题的本质,首先要理解:什么是模型?模型是一组假设,这组假设一定是基于某个具体的问题所提出的。也就是说,当我们去完成一个机器学习的任务时,一定是为了解决某一个问题,而这个问题本身会对数据的类型、数据的收集过程、数据的预处理等作出限制,这些限制不能够直接通过观察数据本身得到(可以认为是一种meta-information),所以就需要通过人为的假设来反映这些元信息。至于一些所谓的model-free的算法,如:聚类、强化学习的model-free方法,只是由于所处理的问题域本身对数据的限制较少,所以在某些方面不需要很强的假设,但仍然是有一些“隐假设”和“弱假设”的。所以,总体上来说,我们希望模型提供一个总体框架,然后用数据对框架进行微调,最终得到一个比较准确的可用的模型。用机器学习的术语来说,就是:先提供一个假设空间,然后在假设空间中搜索最合适的假设。
为不确定性建模
大多数情况下,我们希望模型具有一定的推断和预测能力,例如,给定一个用户信息与信用评级之间的关系模型:
其中:表示信用评级,取值为1~k,代表k个信用等级,表示由用户各项信息所组成的向量,是模型的未定参数。
现实中,我们不但希望知道给定用户的信用评级,而且希望知道给出这个评级时模型的确定性程度(也可称为:可信任度)。概率论为不确定性的建模提供了极好的工具,如下式所示:
其中,p表示概率分布函数,表示条件概率。
关于不确定性的完整建模,涉及到很多其他的理论和概念,包括信息论, 随机过程,混沌理论,贝叶斯定理,模型的固有局限性等,在此不做展开。
模型与数据结构
实际应用中的模型都比较复杂,往往包含成千上万的变量,即X的维数n很大,所需要确定的参数也同样是高维的,并且各个变量之间也有关联关系,因此我们需要利用先验知识为多个变量间的关系建模。高维空间相对于低位空间的处理来说比较困难,所以一个重要的直觉是:对高维空间分解成多个子空间,在各个子空间中处理得到解后,再合成高维空间中的解。条件概率的乘法公式可以实现这样的分解:
如果两个变量是相互独立的,那么可以进一步简化成:
前面提到,机器学习是统计学和计算机科学的联姻,而计算机科学提供的最强大的两个工具是:数据结构和算法。在众多数据结构中,图是最通用的一种数据结构,如果我们能够把上述模型的数学公式表示成图的形式,不但可以提供直观的可视化展示,而且可以借助计算机科学中现有的算法来完成各类计算过程。
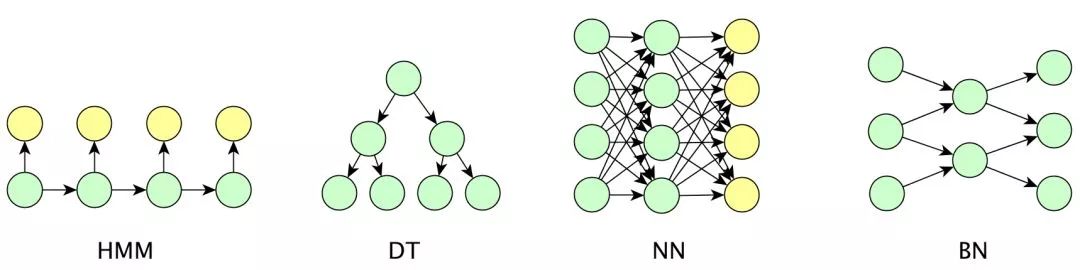
在上述的概率模型中,如果将变量用图的节点来表示,变量间的依赖关系用有向边来表示,那么就能够实现模型与图的对应。概率图模型就是这样一种思路。通过将模型与各种数据结构(图、树、森林、链表等)的结合,我们可以得到以下经典模型:
贝叶斯网(BN),马尔科夫随机场(MRF),条件随机场(CRF),隐马尔科夫模型(HMM),决策树(DT),随机森林,神经网络(NN)等。而其他模型,如支持向量机(SVM),线性回归模型,逻辑斯底分类模型都是上述模型的进一步简化。
以下给出一些模型的简单图示:
小结
本节我们介绍了机器学习中模型的一个通用理论框架。接下来,我们需要理解如何通过数据来对模型做微调,即:确定参数。这个过程也称为“学习”或“训练”。
二
学习=训练=优化=拟合
“学习”的本质


